简介
本篇blog将介绍神经网络的入门基础——深度感知机,简单介绍下深度感知机的结构,分析数据是如何前馈的,误差又是如何后馈,即误差如何反向传播,这是神经网络优化算法的核心。
背景介绍
神经网络的灵感取自于生物上的神经元细胞,如下图所示: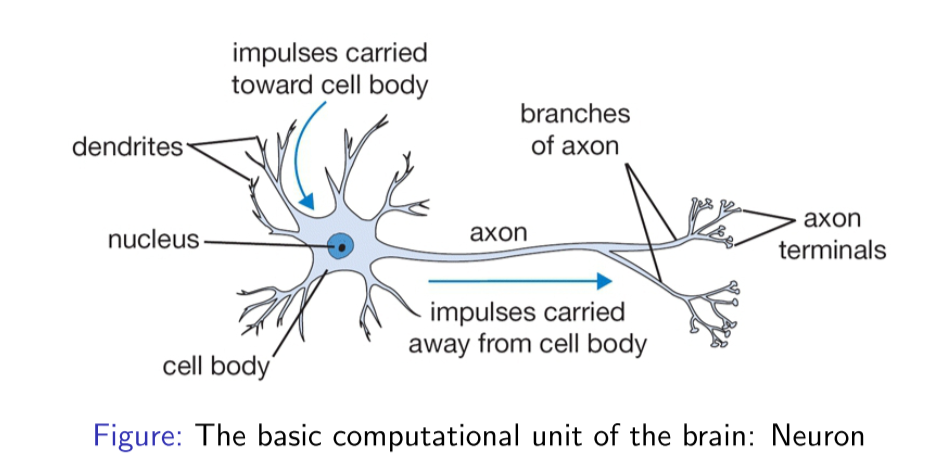
这是人体神经元的基本构成,其中树突主要用于接收其他神经元的信号,轴突用于输出该神经元的信号,数以万计的神经元相互合作,使得我们人类能够进行高级的思考,能够不断地对新事物进行学习。因此,我们就希望仿照人类神经网络的结构,搭建一种人为的神经网络结构,从而使其能够完成一些计算任务,这也是神经网络名字的由来。
节点结构
神经网络中计算的基本单元是神经元,一般称作「节点」(node)或者「单元」(unit)。每个节点可以从其他节点接收输入,或者从外部源接收输入,然后计算输出。每个输入都各自的「权重」(weight,即 w),用于调节该输入对输出影响的大小,节点的结构如图所示: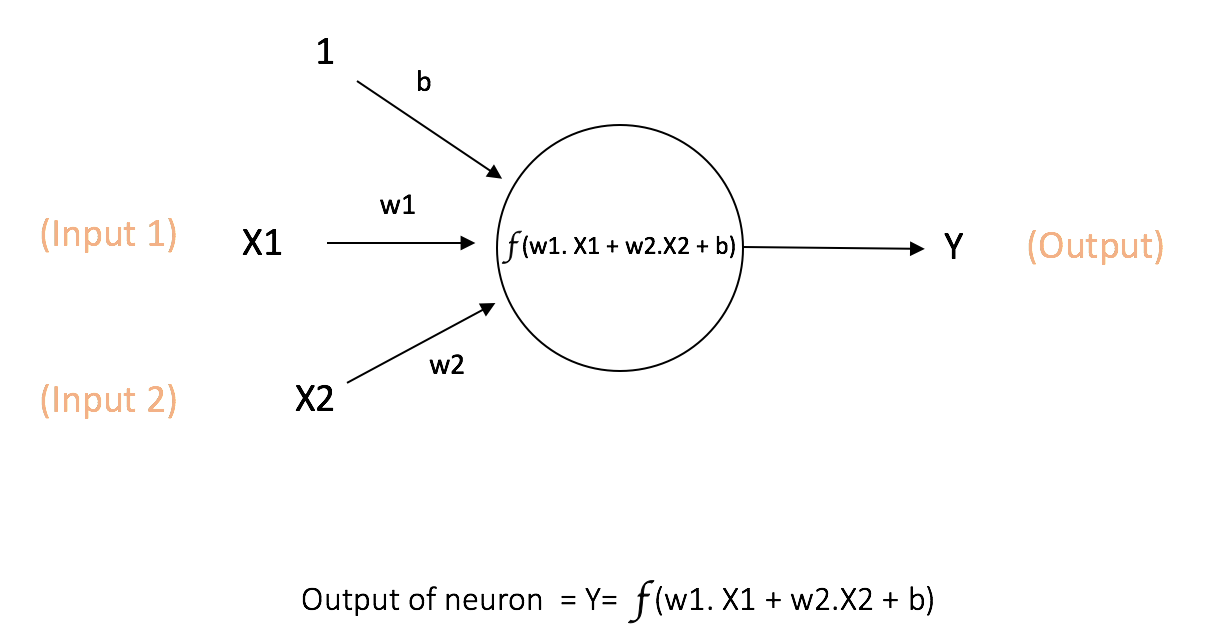
其中x1,x2作为该节点的输入,其权重分别为 w1 和 w2。同时,还有配有「偏置b」(bias)的输入 ,偏置的主要功能是为每一个节点提供可训练的常量值(在节点接收的正常输入以外)。神经元中偏置的作用,详见这个链接:(https://stackoverflow.com/questions/2480650/what-is-the-role-of-the-bias-in-neural-networks)
神经元的输出 Y 按照上图中的计算方式进行,其中函数 f 叫做激活函数,一般采用非线性函数,其作用是将非线性引入神经元的输出。因为大多数现实世界的数据都是非线性的,我们希望神经元能够学习非线性的函数表示,如果激活函数仍然是线性的,那么根据线性可叠加的原理,整个函数模型仍然是线性的,那么就无法解决我们遇到的问题(例如异或),因此激活函数非线性这一点非常重要。
每个(非线性)激活函数都接收一个数字,并进行特定、固定的数学计算 。在实践中,可能会碰到几种激活函数:
Sigmoid(S 型激活函数):输入一个实值,输出一个 0 至 1 间的值 σ(x) = 1 / (1 + exp(−x))
tanh(双曲正切函数):输入一个实值,输出一个 [-1,1] 间的值 tanh(x) = 2σ(2x) − 1
ReLU:ReLU 代表修正线性单元。输出一个实值,并设定 0 的阈值(函数会将负值变为零)f(x) = max(0, x)
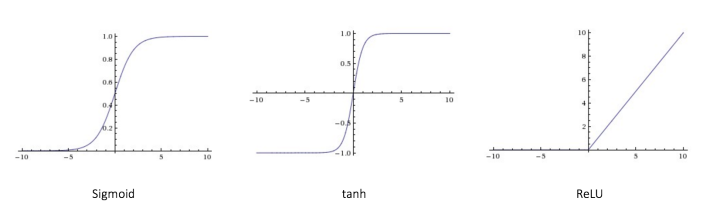
如图所示,该图为不同的激活函数的曲线图,第一种就是逻辑回归使用的激活函数,往往应用于二分类;在神经网络中,我们往往更倾向于使用最后一种relu函数作为激活函数。
MLP结构
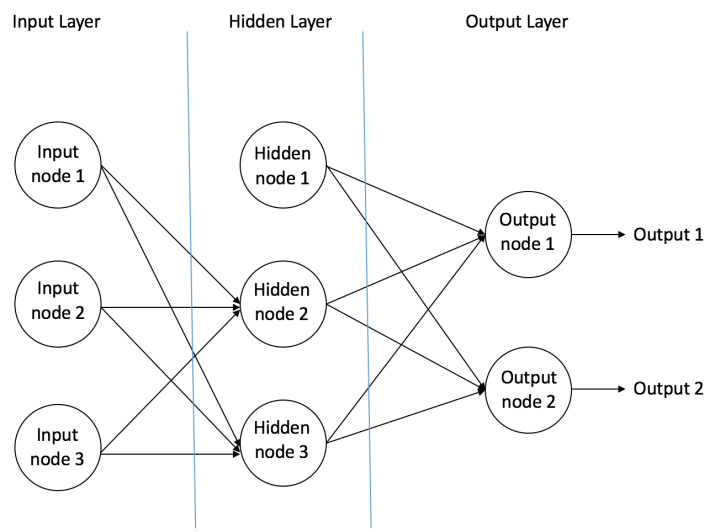
MLP的结构如图所示,主要由三部分组成,至少要有一个隐藏层。
输入节点(Input Nodes):输入节点从外部世界提供信息,总称为「输入层」。在输入节点中,不进行任何的计算,仅向隐藏节点传递信息。
隐藏节点(Hidden Nodes):隐藏节点和外部世界没有直接联系(由此得名)。这些节点进行计算,并将信息从输入节点传递到输出节点。隐藏节点总称为「隐藏层」。尽管一个前馈神经网络只有一个输入层和一个输出层,但网络里可以没有隐藏层(如果没有隐藏层,激活函数选择sigmod,那么就变成逻辑回归了),也可以有多个隐藏层。
输出节点(Output Nodes):输出节点总称为「输出层」,负责计算,并从网络向外部世界传递信息。
数据前馈
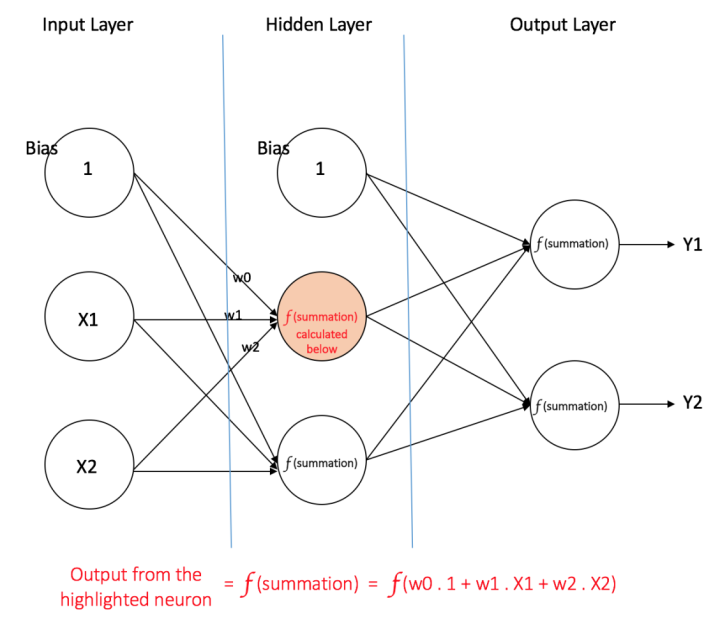
以之前的结构为例:
(1) 输入层:输入层有三个节点。偏置节点值为 1。其他两个节点,X1 和 X2 取自外部输入(皆为根据输入数据集取的数字值)。和上文讨论的一样,在输入层不进行任何计算,所以输入层节点的输出是 1、X1 和 X2 三个值被传入隐藏层。
(2) 隐藏层:隐藏层也有三个节点,偏置节点输出为 1。隐藏层其他两个节点的输出取决于输入层的输出(1,X1,X2)以及连接上所附的权重。图中显示了隐藏层(高亮)中一个输出的计算方式。其他隐藏节点的输出计算同理。需留意 f 指代激活函数。这些输出会作为输出层的输入。
(3) 输出层:输出层有两个节点,从隐藏层接收输入,并执行类似高亮出的隐藏层的计算。这些作为计算结果的计算值(Y1 和 Y2)就是多层感知器的输出。
给出一系列特征 X = (x1, x2, …) 和目标 Y,一个多层感知器可以以分类或者回归为目的,学习到特征和目标之间的关系,从而建立模型。为了更好的理解多层感知器,我们举一个例子。假设我们有这样一个学生分数数据集: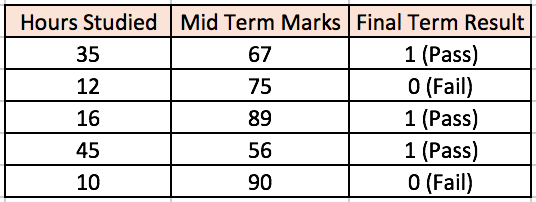
两个输入栏表示了学生学习的时间和期中考试的分数。最终结果栏可以有两种值,1 或者 0,来表示学生是否通过的期末考试。例如,我们可以看到,如果学生学习了 35 个小时并在期中获得了 67 分,他 / 她就会通过期末考试。现在我们假设我们想预测一个学习了 25 个小时并在期中考试中获得 70 分的学生是否能够通过期末考试。
这是一个二元分类问题,那么多层感知机又是如何利用这么多的数据的到我们想要的结果呢?
首先,对网络中所有的权重进行随机分配,假设从输入连接到这些节点的权重分别为 w1、w2 和 w3(如图所示)。神经网络会将第一个训练样本作为输入,那么网络的输入=[35, 67],涉及到的节点的输出 V 可以按如下方式计算(f 是类似 Sigmoid 的激活函数):V = f(1×w1 + 35×w2 + 67×w3),最后的得到我们的输出结果,假设输出层两个节点的输出概率分别为 0.4 和 0.6(因为权重随机,输出也会随机),但是我们期望的网络输出(目标)=[1, 0],可以看出两者之间的差距还是蛮大的,那么我们该如何调整权重,使得输出的结果更加接近目标呢?这一点,我将在下一部分讲解,也就是我们的优化算法。
误差后馈
下面我们将介绍一个多层感知器如何调整权重:
反向传播误差,通常缩写为「BackProp」,是几种训练人工神经网络的方法之一。这是一种监督学习方法,即通过标记的训练数据来学习(有监督者来引导学习)。简单说来,BackProp 就像「从错误中学习」。监督者在人工神经网络犯错误时进行纠正。一个人工神经网络包含多层的节点: 输入层,隐藏层和输出层。相邻层节点的连接都有配有「权重」。学习的目的是为这些边缘分配正确的权重。通过输入向量,这些权重可以决定输出向量。在监督学习中,训练集是已标注的。这意味着对于一些给定的输入,我们知道期望的输出(标注)。
反向传播算法:最初,所有的边权重(edge weight)都是随机分配的。对于所有训练数据集中的输入,人工神经网络都被激活,并且观察其输出。这些输出会和我们已知的、期望的输出进行比较,误差会「传播」回上一层。该误差会被标注,权重也会被相应的「调整」。该流程重复,直到输出误差低于制定的标准。上述算法结束后,我们就得到了一个学习过的人工神经网络,该网络被认为是可以接受「新」输入的。该人工神经网络可以说从几个样本(标注数据)和其错误(误差传播)中得到了学习。
现在我们知道了反向传播的原理,我们回到上面的学生分数数据集。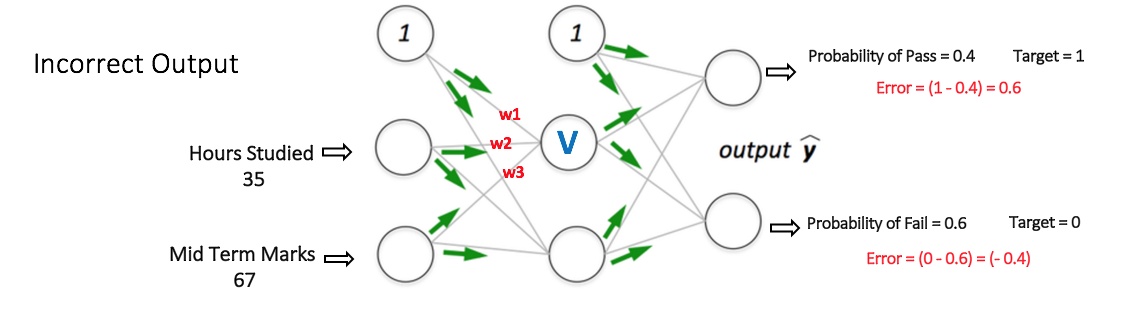
如图所示的多层感知器,其输入层有两个节点(除了偏置节点以外),两个节点分别接收「学习小时数」和「期中考试分数」。感知器也有一个包含两个节点的隐藏层(除了偏置节点以外)。输出层也有两个节点——上面一个节点输出「通过」的概率,下面一个节点输出「不通过」的概率。
在分类任务中,我们通常在感知器的输出层中使用 Softmax 函数作为激活函数,以保证输出的是概率并且相加等于 1。Softmax 函数接收一个随机实值的分数向量,转化成多个介于 0 和 1 之间、并且总和为 1 的多个向量值。所以,在这个例子中:概率(Pass)+概率(Fail)=1
在上一小节,我主要介绍了数据的前向传播,那么下面来重点讲解误差反向传播和权重更新:计算输出节点的总误差,并将这些误差用反向传播算法传播回网络,以计算梯度。接下来,我们使用类似梯度下降之类的算法来调整网络中的所有权重,目的是减少输出层的误差。下图展示了这一过程(暂时忽略图中的数学等式)。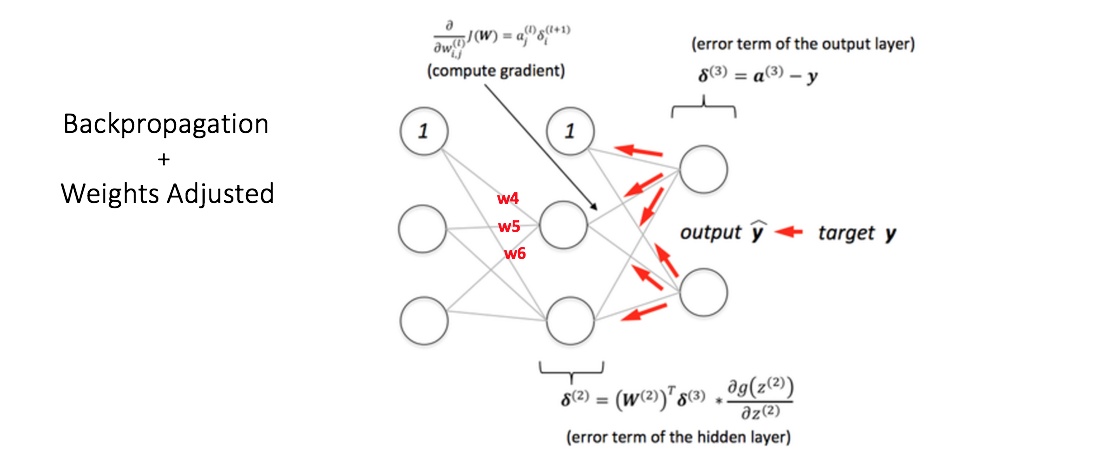
假设附给节点在反向传播和权重调整之后的新权重分别是 w4,w5 和 w6。接着用我们数据集中的其他训练样本来重复这一过程,不断迭代,这样,我们的网络就可以被视为学习了这些例子,从而使得输出误差不断减小,直到误差减小到一个合适的范围,那么我们就可以停止迭代了。这样我们就能够获得较为精准的预测模型。现在,如果我们想预测一个学习了 25 个小时、期中考试 70 分的学生是否能通过期末考试,我们可以通过前向传播步骤来计算 Pass 和 Fail 的输出概率。
更具体的bp算法推导可以参考:http://home.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
过拟合与欠拟合
过拟合是指训练误差小,但是泛化误差较大;欠拟合是指训练误差大,泛化误差也很大。下面,我主要针对神经网络做一些相关的讨论
神经网络相比于其他的机器学习算法,其功能更为强大,只要给予神经网络足够多的节点,理论上它就能拟合任意的模型,但是也有缺点,就是容易产生过拟合。那么产生过拟合的根本原因是什么呢?那是因为我们并不能保证训练样本完全正确,也就是可能存在部分的样本存在误导性,所以当神经网络功能过于强大时,很容易连训练样本中的错误样本也学习了,从而导致只能具有很低训练误差,而不能拥有较低的泛化误差,也就是我们所说的过拟合。最常见的方法之一是提前终止学习,如图所示: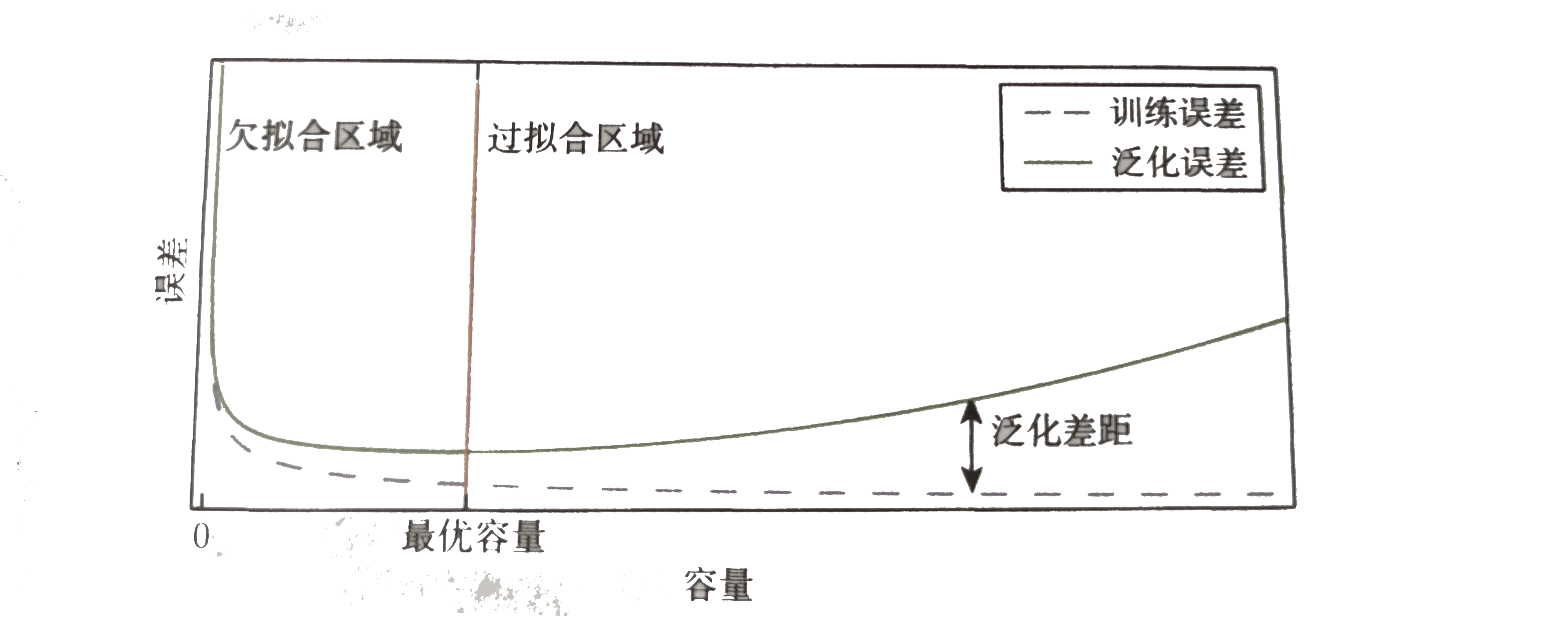
在合适的迭代次数终止算法从而达到最优容量(泛化误差最低),但是最佳迭代次数并不好找,往往需要多次测试才有可能找到,因此更常用的方法是“Dropout”防止过拟合,下面来重点讲解:
什么是Dropout
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
在2012年,Alex、Hinton在其论文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout算法,用于防止过拟合。并且,这篇论文提到的AlexNet网络模型引爆了神经网络应用热潮,并赢得了2012年图像识别大赛冠军,使得CNN成为图像分类上的核心算法模型。
随后,又有一些关于Dropout的文章《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》。
从上面的论文中,我们能感受到Dropout在深度学习中的重要性。那么,到底什么是Dropout呢?
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。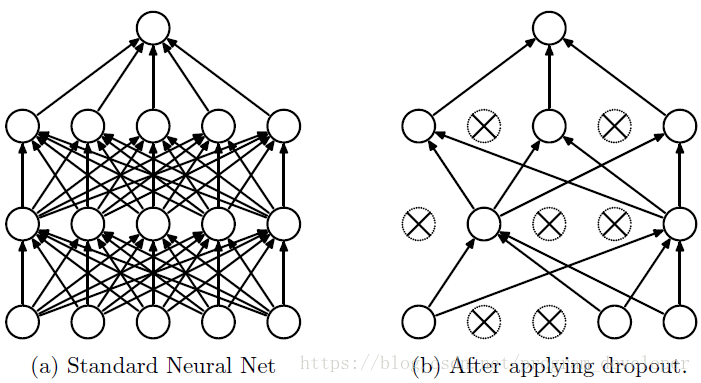
Dropout工作流程及使用
Dropout具体工作流程
假设我们要训练这样一个神经网络,如图所示。
输入是x,输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图中虚线为部分临时被删除的神经元)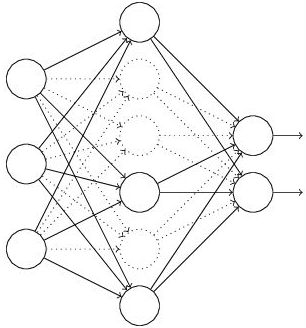
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小(这个量可以自己选)的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
为什么说Dropout可以解决过拟合
(1)取平均的作用: 先回到标准的模型,即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
初始参数的选取
在许多参考文献中都提到,对于神经网络而言。模型与优化的选取至关重要,当然这无可厚非,但是初始值的选取对于模型的训练也有一定程度的影响,不合适的初始值可能会耗费大量的训练时间,甚至有可能无法达到我们预期的目标,因此在这里简单介绍下初始值选取的一般规则:
(1) 禁止将所有的权重均设置为同一个常数c,否则bp算法将会失效,所有的权重将不会更新!
(2) 一般令权重W的初始值服从0均值的高斯分布,该分布的方差应该选择合适的大小,如果过小会导致梯度消失,过大会导致权重无法收敛。
(3) 方差选取的参考意见:第一种:$\sigma^{2}=2 /\left(n_{i n}+n_{o u t}\right)$,其中$n_{\text {in}}$ 与 $n_{\text {out}}$分别为该层的上一层节点数量与下一层节点数量;第二种:$\sigma^{2}=2 / n_{\text {in }}$

