简介
卷积神经网络主要是对图片进行处理,比如说人脸识别等等。该种算法参考了人眼视觉的某些特性,利用某些特殊的卷积核对图像进行处理分割。下面,我将对卷积神经网络的来源,架构,优化,优劣以及应用等方面进行简单介绍。
引言
在2012年,卷积神经网络第一次正式投入使用,Alex Krizhevsky曾使用该网络赢得2012年的图像识别竞赛,并将该网络错误率从0.26降到0.15,这在当时是一个非常巨大的进步。目前,卷积神经网络仍是一种非常流行深度学习算法,该算法使用特殊的卷积核对图片进行处理,提取一些高维特征,然后对这些高维特征的处理以达到我们的目的,所以这种方法用于处理图像方面的问题事非常有效!
问题描述
对于图像处理问题,首先我们先举一个基础例子:图像分类!简单来说,图像分类就是输入一个图像,输出该图像中物品的类别或者说分到每个类的概率大小,以下图为例:
当输入图像如上图所示,我们希望算法能够告诉我们这是狗,或者80%的概率是狗。
对于人类而言,对于物品的识别能力是与生俱来的,我们天生就能够识别物品,并且这项能力会伴随着我们的能力逐渐增长,因此我们往往不需要过多的思考就能够辨别出我们所处的环境与位置。所以,我们在辨识物品的时候,与神经网络算法不同,不需要特意的对物品进行打标签,因为这项能力主要来源于我们的知识储备以及对于不同图像环境的学习能力,而这些对于机器而言都是不具备的,因此我们就想要提出一种方法,使得机器具备学习并识别图像的能力,CNN算法因此就被提了出来!
电脑能看见什么
当电脑看见一幅图像时,它看到的是一系列像素值,举个例子来说吧,电脑可能读取一个32323的数字矩阵(分别对应RGB),矩阵的大小由图片的大小与分辨率决定。现在我们来具体举一个实际的例子方便理解,假如我们有一个JPG格式的彩色照片,其大小是480×480,那么我们可以用用480×480×3的矩阵来表示该向量。其中,矩阵中每个数字都是在0~255之间,用于描述该点的像素在RGB上的灰度大小。这些数字对于我们人类在对图像分类的时候毫无意义,但是对于电脑而言却是非常有用,电脑判别图像的方式就是对输入的数字矩阵进行相关的处理,最终输出结果!
任务目标
根据上面的描述我们知道,电脑看到的图像就是一系列数字矩阵,那么我们应该如何处理才能得到我们想要的结果呢?首先,我们希望电脑能够对所有照片进行分析,找到它们之间的不同的点,接下来我们再进行更深一步的操作,即找到这些照片独特的特点,比如说对于一个大象的照片,算法可以找到其长长的鼻子,然后我们根据这样的一个或或者多个特征,对该图像进行分类。真正实际应用时,我们对图片中的边缘与曲线信息这样的低维特征进行提取,通过一系列卷积层来获得更加抽象的高维特征,这就是卷积神经网络的主要原理,下面我们来探讨下算法中的细节问题!
卷积神经网络的启发
卷积神经网络受生物研究中视皮层启发得到,在人眼的视皮层中,有一小部分细胞对看见事物中的特殊部分非常敏感。这个观点由Hubel和 Wiesel在1962年的一个有趣的实验中得到论证,他们证明了在大脑中有部分独立的细胞仅对视野中某些确定事物的轮廓有反应。比如说有一些神经细胞仅在看到了垂直的轮廓时兴奋激活,而有一些其他的神经细胞则只会在看到水平的轮廓时激活。之所以会产生这样的现象,是因为这些特殊的神经细胞都是由一种柱状结构构成,对视觉效果十分敏感,于是我们就提出能够在我们的算法中,也设置类似这样的一种特殊结构,用于提取图片中的信息呢?这就是卷积神经网络的起源。
CNN的结构
现在,我们回到正题上,CNN到底是如何具体的处理图像的呢?下面我先简单的描述下:输入图像—>卷积—>非线性变换—>池化—>全连接层—>输出。根据前面的描述可知,输出可以是单个的类,也可以是最能描述图像的类的概率。接下来,我们将重点介绍每一层的作用。
第一层:卷积层
在卷积神经网络网络中,第一层网络我们一般都设置为卷积层,在该层我们将进行如下操作:输入图像,例如对神经网络输入一个32×32×3的一个数字矩阵,然后对其进行卷积操作。对于卷积操作,我举一个例子来简单解释一下吧,如下图所示: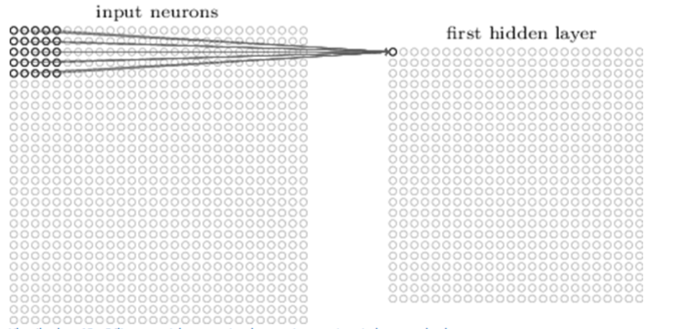
假设有一个手电筒,它的照射范围是5×5,我们先令其照在左上角,如上图的左边所示,,然后令手电向右滑动,遍历图像所有的部分。在神经网络中,我们称这样的“手电筒”为卷积核,其实就是一个数字矩阵;“手电筒”的照射范围就是这个数字矩阵的维度!值得注意的一点是,卷积核的深度要与图像的深度一致,比如说图片是32×32×3的矩阵,那么卷积核就要是n×n×3的矩阵。仍以上图为例,演示下图像是如何卷积的:刚开始卷积核位于左上角,卷积核上的每一个数字与图像中对应的位置的数字相乘然后求和,这样我们就可以得到在该位置处卷积的到的结果,然后滑动卷积核,使其遍历到图像上的所有位置,这样我们就可以得到图像卷积后的结果。例如,对于32×32×3的图像我们采用5×5×3的卷积核进行卷积,可以得到28×28×3的矩阵,该矩阵就是我们卷积后得到的结果。
根据上述描述,我可以知道,我们设置了一个卷积核对图像进行遍历操作,得到一个卷积后的结果,这个结果可以帮助我们检测图像中是否存在某些特征,因此我们往往称卷积核为特征识别器。所谓特征,在这里我指的是直线轮廓,曲线轮廓,纯色区域这样的特征,因为这些特征时所有照片都具备的简单特征。下面我来据图介绍下,卷积核是如何筛选特征的,假设存在某一7×7×3的卷积核,如下图所示: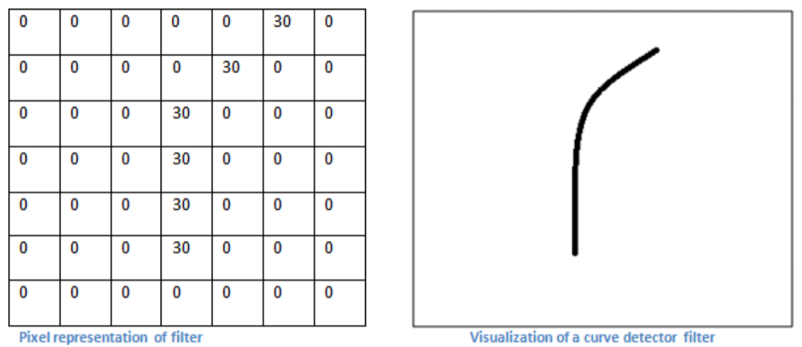
为了简化我们的问题,我们先只考虑其中的一个7×7的卷积核,如图所示,该卷积核在沿着曲线的方向上具有更高的数值!我们将该卷积核应用于下面图像的左上角,具体计算方法在上面已经说过,因此不再赘述。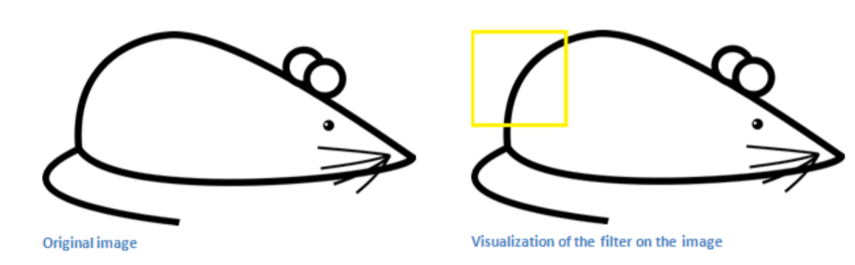
图片上对应位置与卷积核相乘求和: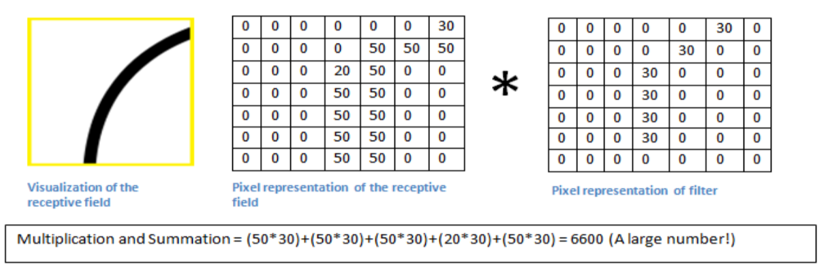
最终得到结果为 6600,这是一个比较大的一个数值,因为卷积核卷积的区域的形状与卷积核非常类似!接下来,我们移动卷积核,如下图所示,在进行卷积操作: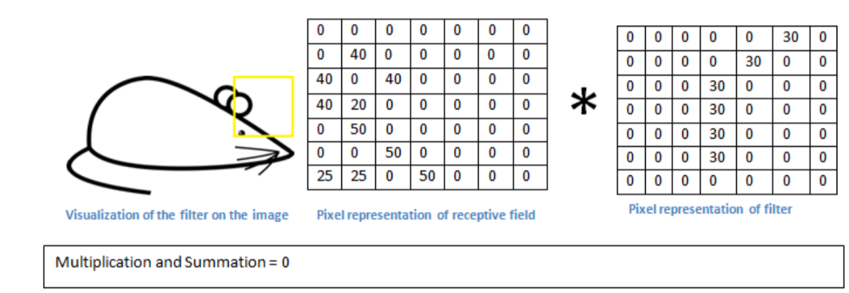
此时卷积结果就会变得非常小,为0,这是因为该区域与卷积核的形状差距巨大!因此卷积核能够起到一种提取特征的效果,如果对应区域的图像与卷积核类似得到数值就会较大,否则就会很小(最小一般为0),在本次演示中,使用的卷积核是一种曲线检测器,检测图片中是否有类似的曲线。在对图片进行卷积操作时,我们可以选用多个卷积核对图片进行处理,以得到多个低级特征,再对低级特征进行卷积就可以提取高级特征,比如检测图片中有没有大象的鼻子。一般来说,使用的卷积核越多,深度越深,其效果就会越强。
其它层
为了拓展CNN以及提高其鲁棒性,我们往往在CNN中添加一些非线性变换(激活函数)以及池化操作,这两个不是我们讲解的重点,因此只是简单的描述下其功能,非线性变换拓展神经网络的功能,使其适应性更强,能够应用于更多的问题;池化能够降低神经网络中的复杂度,有效减少训练时间以及避免神经网络出现过拟合!
利用前面的一些操作,我们可以检测到图片中高级特征,而在最后一层我们往往使用全连接层的方式连接,其作用如下:
在这一层,其输入往往是一个n×m的矩阵,输出一个N维向量,其中N为图像可能的类别种类。例如,对于手写数字的识别,N应该是10,因为有10位数字。这个N维向量中的每一个数字都表示某个类的概率。举个例子,如果结果向量为[0,0.1,0.1,0.75,0,0,0,0,0,0.05],那么这个图片,有10%的概率是1;有10%的概率为2;有75%的概率为3;有5%的概率为9。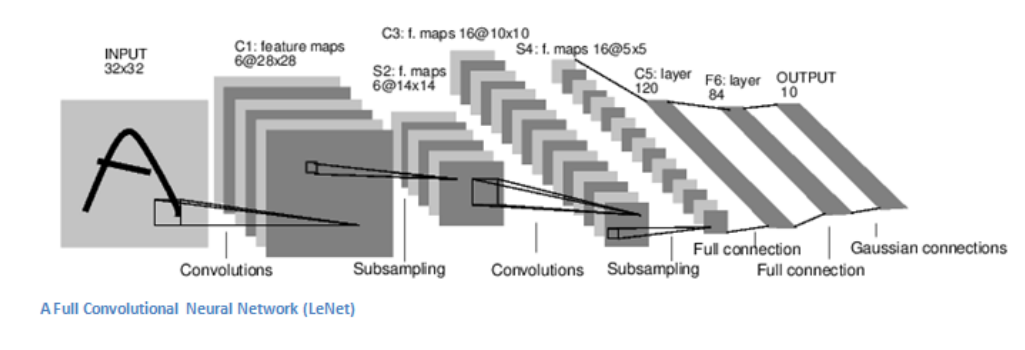
卷积神经网络的训练
卷积神经网络是一种监督学习算法,其训练方式与一般的神经网络类似,核心是bp算法,在这里做简单的介绍“在刚刚开始训练的时候,我们将神经网络所有的权重与卷积核随机初始化,将数据钱箱传递,根据损失函数将误差后向传播,以一个常用的损失函数为例:MSE(均方误差)
利用bp算法更新卷积核与权重的值,使其损失函数较小达到算法的最优容量。
ps:反向传播时会把卷积核和图片展开,然后就同全连接的反向传播一样训练了!

