论文原文地址:https://cleverbobo.github.io/file/hmp.pdf
仅供学术交流使用~
摘要
The problem of predicting human motion given a sequence of past observations is at the core of many applications in robotics and computer vision. Current state-of-the-art formulate this problem as a sequence-to-sequence task, in which a historical of 3D skeletons feeds a Recurrent Neural Network (RNN) that predicts future movements, typically in the order of 1 to 2 seconds. However , one aspect that has been obviated so far , is the fact that human motion is inherently driven by interactions with objects and/or other humans in the environment.
In this paper , we explore this scenario using a novel context-aware motion prediction architecture. We use a semantic-graph model where the nodes parameterize the human and objects in the scene and the edges their mutual interactions. These interactions are iteratively learned through a graph attention layer , fed with the past observations, which now include both object and human body motions. Once this semantic graph is learned, we inject it to a standard RNN to predict future movements of the human/sand object/s. We consider two variants of our architecture, either freezing the contextual interactions in the future of updating them. A thorough evaluation in the “Whole-Body Human Motion Database” [29] shows that in both cases,our context-aware networks clearly outperform baselines in which the context information is not considered.
翻译:
在智能机器人和计算机视觉的许多应用中,根据过去的一系列对人类动作的观察结果来预测人体运动是一个核心问题。目前,主要应用Seq2Seq技术来处理相关的领域,其中采用3D骨骼(人行为动作的抽象表达方式)作为历史输入,为循环神经网络(RNN)提供信息从而预测未来的运动。这个未来的时间段通常控制在1到2秒的时间内。然而,到目前为止,有一个观点已被人们否定——人类的运动从本质上来说,是由与环境中的物体或其他人的互动所驱动的。
在本文中,我们使用一种新的上下文感知的运动预测架构来预测人类行为。我们使用一种语义图模型,图中的节点代表场景中参数化后的人或物,以及它们之间的相互作用(具体表现为权重)。这些权重的大小是通过在图表注意力层不断迭代学习的,影响迭代的因素有过去的观察,现在包括物体和人体运动。一旦这个语义图模型被训练成功,我们将它与一个标准的RNN模型相结合,来预测人/物的未来运动。目前,我们主要考虑架构的两种变体,即是否在将来更新它们的权重时,保留上下文交互。在“全身人体运动数据库”[29]中进行的全面评估表明,在这两种情况下,我们的上下文感知网络性能明显优于没有考虑上下文信息。
关键字解析:人类行为预测,上下文感知,注意力机制,RNN
实验数据解析
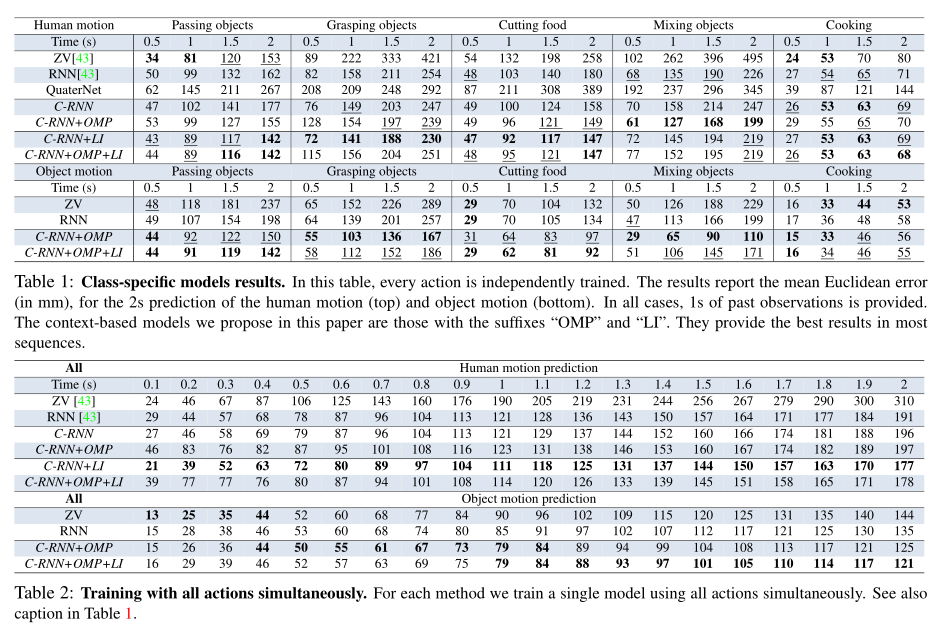
预测目标:human motion(人类行为)、object motion(物体行为)
模型:ZV,RNN,QuarterNet,C-RNN,C-RNN+OMP,C-RNN+LI,C-RNN+OMP+LI
行为种类:Passing objects(路过)、 Grasping objects(抓取)、 Cutting food(切菜) 、Mixing objects(搅拌)、 Cooking(做饭)
ps:中间的数字大小代表误差,用黑体表注的为误差(L2范数)最小的情况
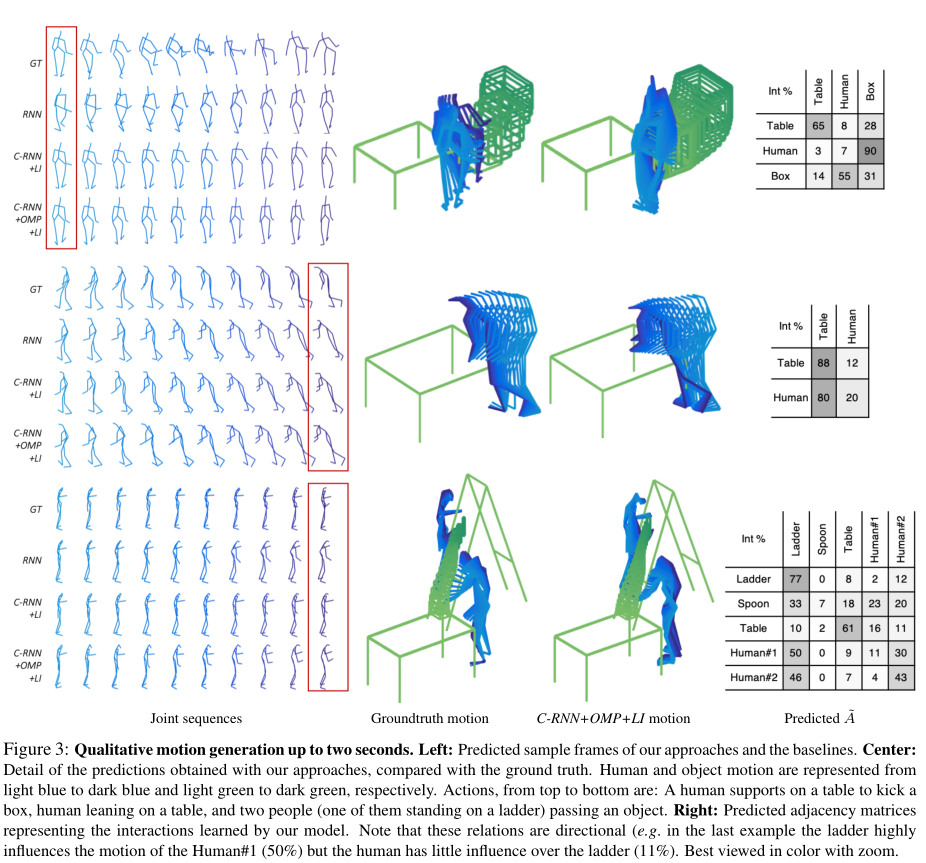
具体的运动生成时间长达两秒钟。最左:使用的预测模型以及基线的预测样本框架;中间:地面人的实际行为的框架图与模型得出的预测框架图,其中,人和物体的运动分别从浅蓝色到深蓝色和从浅绿色到深绿色来表示。从上到下的动作依次是一个人支撑在桌子上踢箱子,一个人靠在桌子上,两个人(其中一个站在梯子上)经过一个物体。最右:预测的邻接矩阵(上侧代表影响因素,左侧代表受影响因素),它代表了我们的模型目标之间的交互。注意,这些关系是有方向的(例如,在最后一个例子中,梯子高度影响人类#1的运动(50%),但是人类对梯子几乎没有影响(11%)。最佳放大彩色视图。
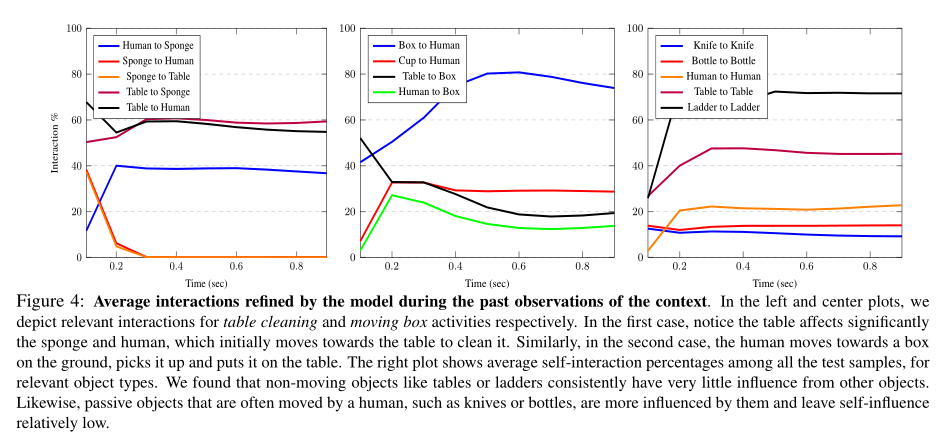
在过去对上下文的观察中,模型细化的平均交互。在左边和中间的图中,我们分别描述了桌子清洁和移动盒子活动的相关交互。在第一种情况下,请注意桌子对海绵和人的影响很大,因为海绵和人最初会移向桌子进行清洁。类似地,在第二种情况下,人类走向地上的一个盒子,把它捡起来,放在桌子上。右图显示了相关对象类型的所有测试样本的平均自交互百分比。我们发现,像桌子或梯子这样的非移动物体总是很少受到其他物体的影响。同样,被动的物体,如刀子或瓶子,经常被人移动,更容易受到它们的影响,自我影响相对较低。
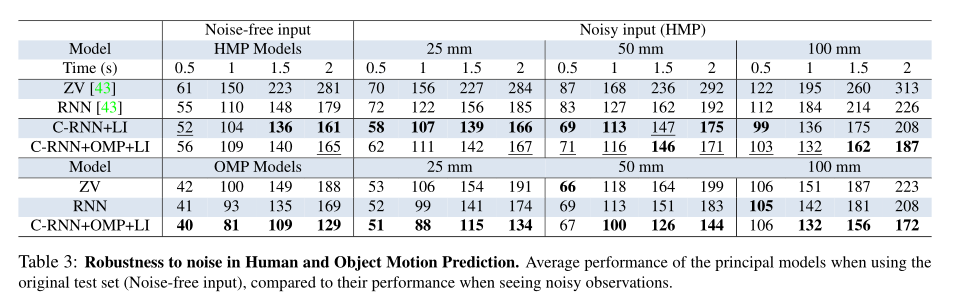
人体和物体运动预测中对噪声的鲁棒性。使用原始测试集(无噪声输入)时主要模型的平均性能,与看到有噪声的观测值时的性能相比。
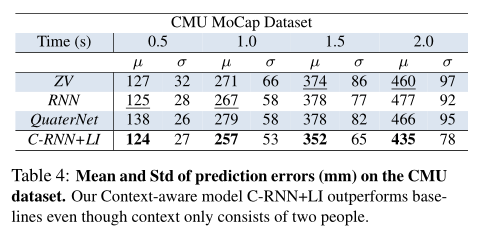
CMU数据集中预测误差的平均值和标准差。
实验结论
In this work, we explore a context-aware motion prediction architecture, using a semantic-graph representation where objects and humans are represented by nodes independently of the number of objects or complexity of the environment. We extensively analyze their contribution for human motion prediction. The results observed in different actions suggest that the models proposed are able to understand human activities significantly better than state-of-art models which do not use context, improving both human and object motion prediction.
翻译:
在本中,我们提出了一种上下文感知的运动预测架构,使用语义图表示。其中,对象和人由节点表示,与对象的数量或环境的复杂性无关。我们广泛分析了它们对人类运动预测的贡献。在不同动作中观察到的结果表明,所提出的模型能够比不使用上下文的最先进的模型更好地理解人类活动,从而改进了人类和物体的运动预测。
论文具体内容
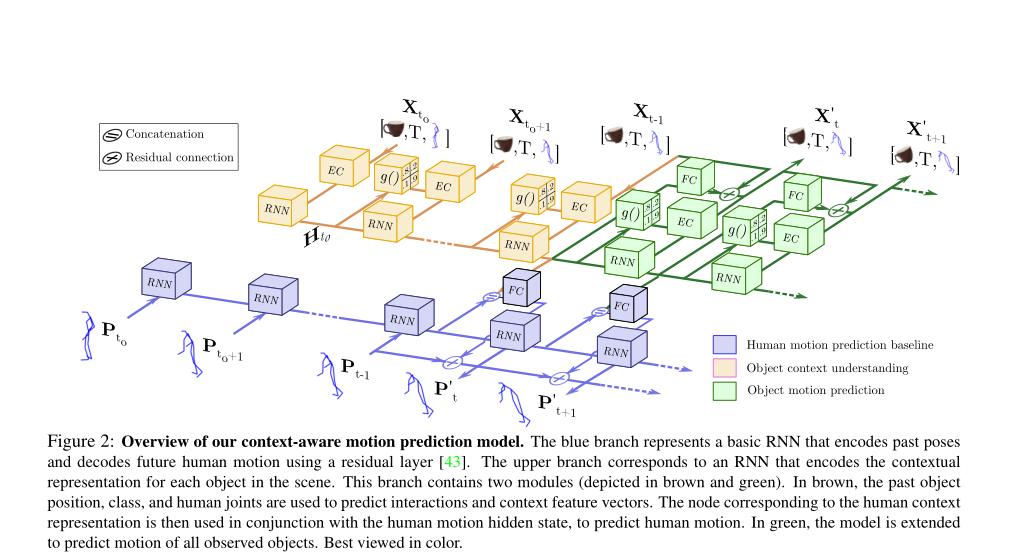
基础架构
该篇论文主要参考了《On human motion prediction using recurrent neural networks》提出的架构,并在此基础上提出了改进,所以先简单介绍下这篇论文介绍了什么。作者比较了其他一些网络结构的人体运动预测结果,发现存在各种各样的问题,比如第一帧不连续,调优困难,模型复杂,只能针对特定动作等等,并提出了以下架构: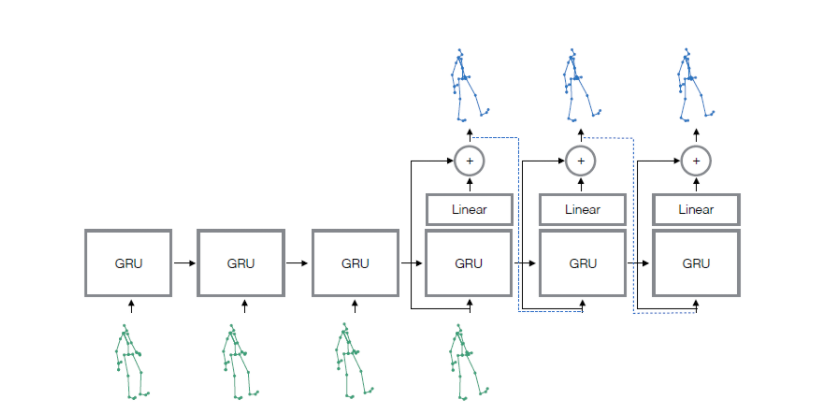
这就是一个典型的sequence2sequence问题,处理序列问题一般都是使用RNN网络,并提出Sampling-based loss 解决超参数调优问题,Residual architecture解决第一帧不连续问题。
sequence2sequence
由encoder和decoder基本结构组成,把输入序列转换为向量,此为编码,然后输出端把预测向量再转化为输出序列,此为解码。sampling based loss
序列问题需要关心时间上的相关性,所以采用RNN结构。但是RNN结构如果只是单纯学习真实值的话,会无法从自己的错误中恢复,如果加入噪音会使得模型难以调参。作者提出了的方法,在训练的过程中,把decoder的输出作为自己的输入。residual architecture
为了解决第一帧预测值不连续的问题,作者提出了residual architecture。原理为添加了速度这一概念,并替换之前认为的预测人体的姿势。即每一帧的预测相当于预测速度的变化值,而不是预测人体姿势本身。所以第一帧的预测便简化为0速度或者接近0速度的预测。而实现方式也较为简单,在每一个RNN模块的输入和输出上添加一个链接,从而学习速度的变化。
实验结论:
- 作者基于sequence-to-sequence模型之上进行了一系列优化用于解决使用RNN所碰到的问题。
- 使用Sampling-based loss,在训练阶段将decoder预测的值加入自己的输入中以解决RNN只学习真实值而不能从自己错误中恢复的问题。
- 使用residual connection,以学习速度代替学习人物姿势本身做到消除第一帧不连续的问题,通过在每个RNN模块建立一条输入和输出的链接实现。
改进部分:背景感知
由于当前使用的主流数据集(仅标注人类运动,不标注背景物块的运动)和某些论证(背景物块的运动不会在本质上影响人类运动)的影响,导致在人类行为预测的问题上下意识忽略背景(context)信息,而这篇论文采用不同的数据集,在原有的模型基础上考虑背景信息,用于提升预测的准确性。
Learning interactions
各个物体之间相互作用关系用一个邻接矩阵$A$表示,刚开始将邻接矩阵$A$初始化为对角阵,也就是各个目标之间相互独立,然后根据每个节点的隐藏状态$H$计算相互作用的大小:并以非监督学习的方式更新不同目标之间的邻接矩阵
Object motion prediction
该文作者除了预测人体运动之外,还同时预测了背景(context)的运动信息。该方法使用过去的背景信息以及每个对象隐藏状态上的residual architecture来预测所有对象的对象运动,预测的位置会被作为下一步的输入。
实验分析
- 相比于其他的模型,改进(“OMP”和“LI”为后缀的模型)的模型能在大多数测试中提供最好的结果,具体数据请参考前面的数据分析。

